Kafka初识之架构之美
Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数组管道、流分析、数据集成和任务关键型应用程序。
Kafka的使用场景
-
消息系统(Messaging)
-
网站活动跟踪(Website Activity Tracking)
-
数据指标(Metrics)
-
日志聚合(Log Aggregation)
-
流处理(Stream Processing)
-
事件驱动(Event Sourcing)
-
日志存储(Commit Log)
以上信息源自官网, 详见: Kafka Use Cases
Kafka基本术语介绍
-
Broker一个单独的
Kafka server就是一个Broker,kafka集群由多个Broker组成 -
Producer生产者,主要工作是往
Broker发送(push)消息 -
Consumer消费者,主要工作是从
Broker拉取(pull)消息 -
Topic主题,存储消息的逻辑概念。可以理解为
rabbitMQ中的queue -
Partition分区,每个
Topic可以划分成多个分区 -
Log分区上存储数据的日志文件,生产者将消息写入分区时,实际上就是写入对应的
Log中 -
Segment段,
Partition里的log文件会划分成多个段 -
Consumer GroupKafka中多个Consumer组成一个Consumer Group,一个Consumer必须只能属于一个Consumer Group -
Replica副本,
Kafka实现高可用的机制,每个Topic至少有一个副本
Kafka架构拓扑图
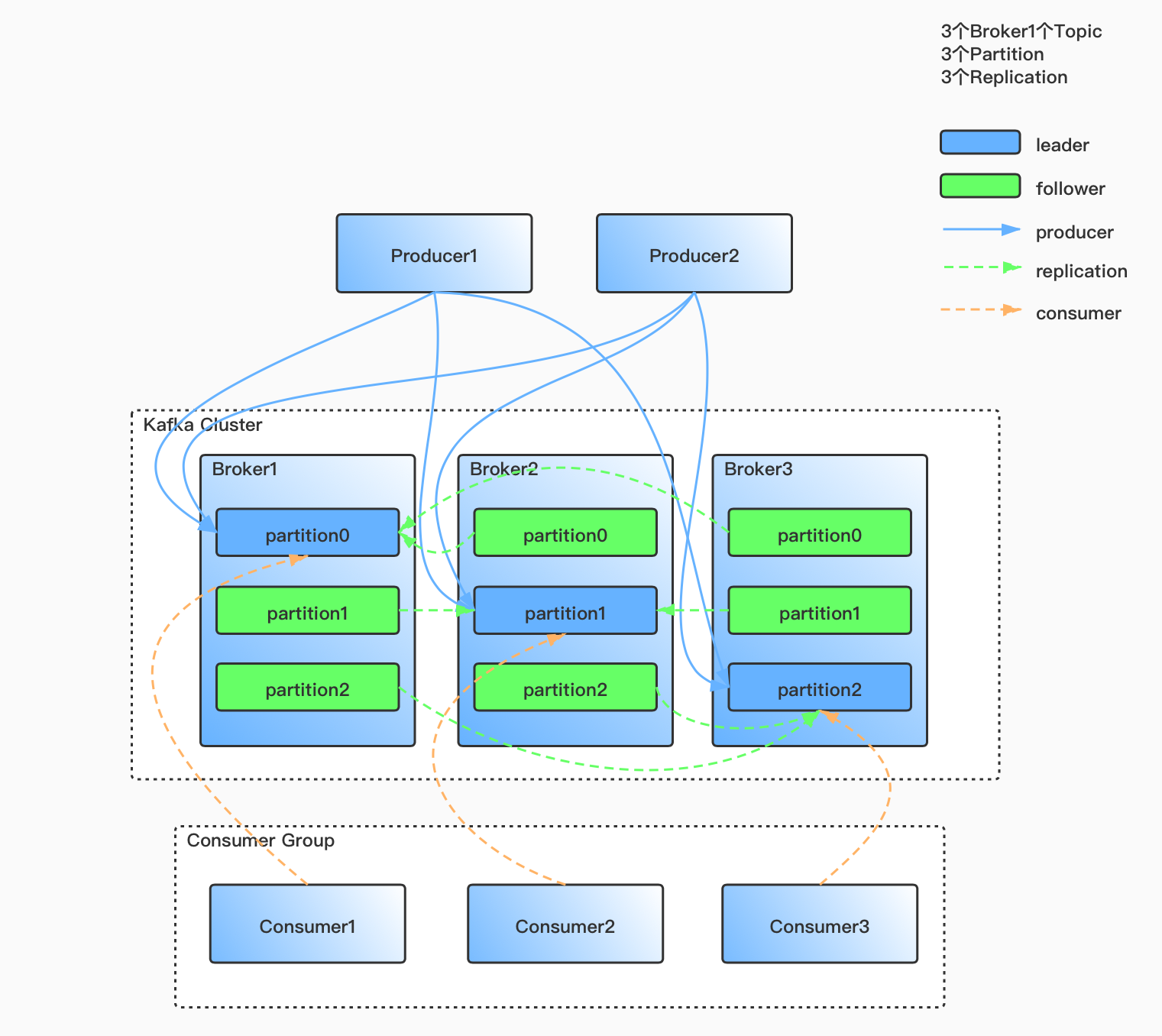
Kafka架构初识
Kafka作为分布式消息中间件,可以很好的替代传统的消息系统。与大多数消息系统相比,具有更好的吞吐量、内置分区、复制和容错能力,这使它在大规模数据应用场景有着明显的性能优势。
最简单的消息系统一般都会包含:生产者producer、消费者consumer、队列queue。如下图所示,仅存一个队列的情况下,生产者先向队列里投递消息,然后消费者再从队列里消费消息。

先不谈Kafka的架构如何,单就上图最简单的场景,如果要提高效率,该怎么做?
在解答这个问题之前,先考虑一下以上mq模型存在哪些缺点:
- 随着消息量增大,当
queue承载的数据量过大时,影响读写性能,同时queue服务也可能宕机 - 当有多个消费者同时消费同一队列里的数据时,需要保证消息分配正确及维护消费位移,而这个过程也是非常耗性能的
- 当生产者发送消息的速度比消费者消费消息的速度快时,
queue服务一直向消费者push消息,消费者可能承受不了压力而宕机
要解决以上问题,通过数据分块、多线程的方式可以缓解,但治标不治本。那么来看看Kafka是如何解决的吧。
Topic & Partition & Segment
顾名思义,主题。Kafka存储消息的逻辑概念,可以简单理解为上面所说的queue。生产者负责向Topic里send消息,消费者负责从Topic里pull消息然后处理。
为了解决一个Topic里的数据文件过大导致的读写性能问题,Kafka将其划分为多个Partition。如下图所示: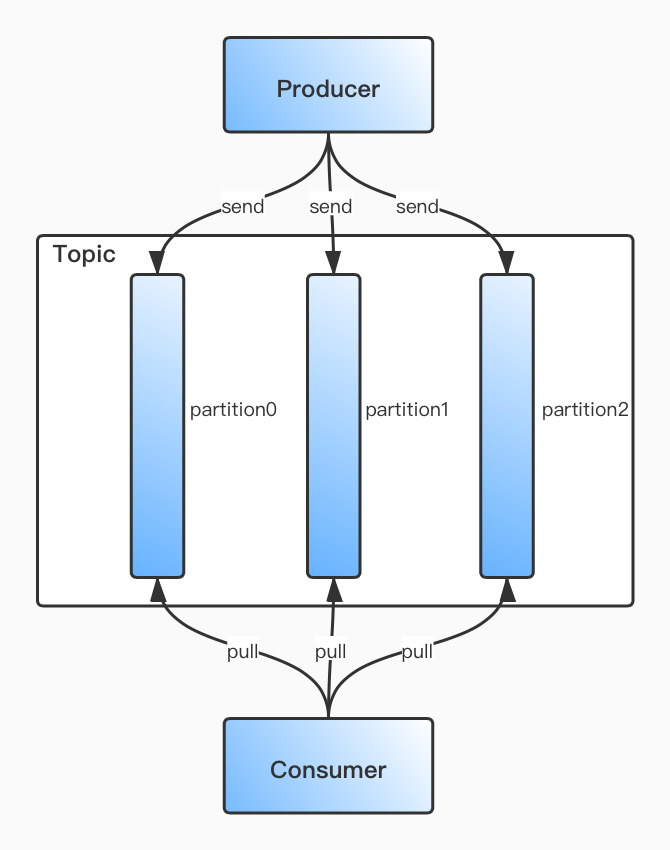
生产者发送消息的时候会按照策略,将消息发送至不同的Partition,发往每个Partiton里的消息会在分区内对应一个偏移量offset且均从0开始依次递增。Kafka保证一个Partiton内的消息是有序的,但无法保证一个Topic内数据的顺序性。如下图所示: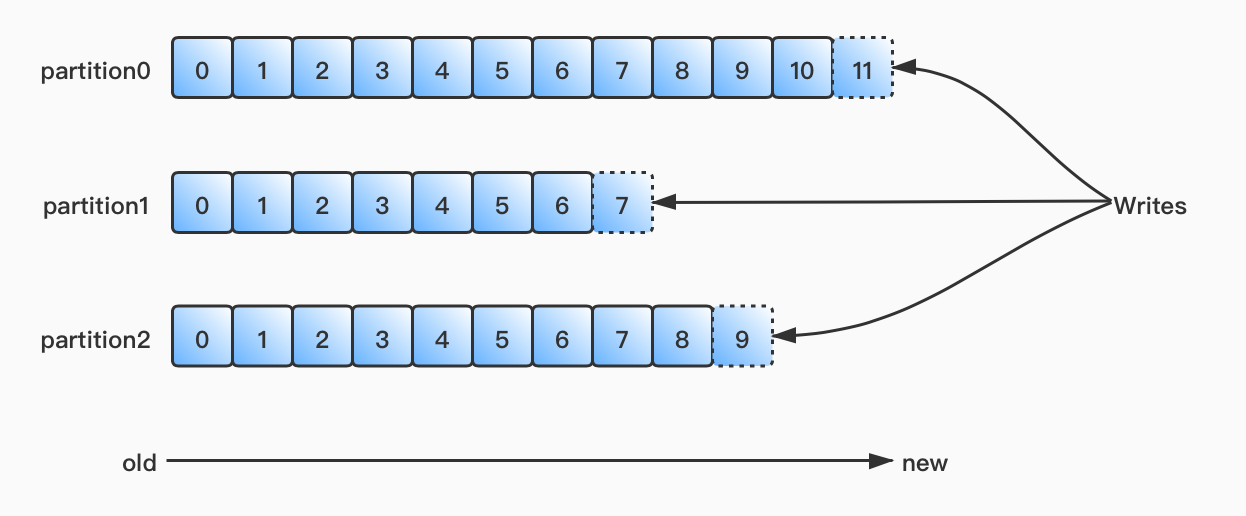
虽然将Topic划分多个Partition可以避免数据过于集中导致的问题,但当Partition中数据过大的时候还是会影响读写性能。因此Kafka再将Partition在物理层面下,通过文件大小、时间等策略细分多段segment,当该段文件大小或时间满足要求,则生成下一段文件数据,每段下均有其对应的索引文件来加速查询。而数据写入的方式则是顺序磁盘IO及文件追加写的形式。
Pull vs Push
首先考虑的一个问题,消费者是应该从Broker那里获取数据,还是Broker应该将数据推给消费者
push: 当生产者发送消息的速度比消费者消费消息的速度快时,Broker服务一直向消费者push消息,消费者可能承受不了压力而宕机。但这样的好处是,Broker不容易积压消息。pull: 当生产者发送消息的速度比消费者消费消息的速度快时,消费者只是消费落后,后面可能赶上。消息积压在Broker上
Replica机制
在分布式系统中,高可用是一个避不开的问题,而Kafka则是通过副本机制实现高可用。
创建Topic时可以指定副本数(至少一个副本)。当创建一个Topic,指定3个分区和3个副本。这样每个分区都有3个副本,Kafka根据一定策略,选出每个分区里的leader和follower,然后尽力确保每个分区的leader落在不同的Broker上。当有Broker宕机的时候,就会触发分区副本选举机制,选举出新的leader。如下图所示: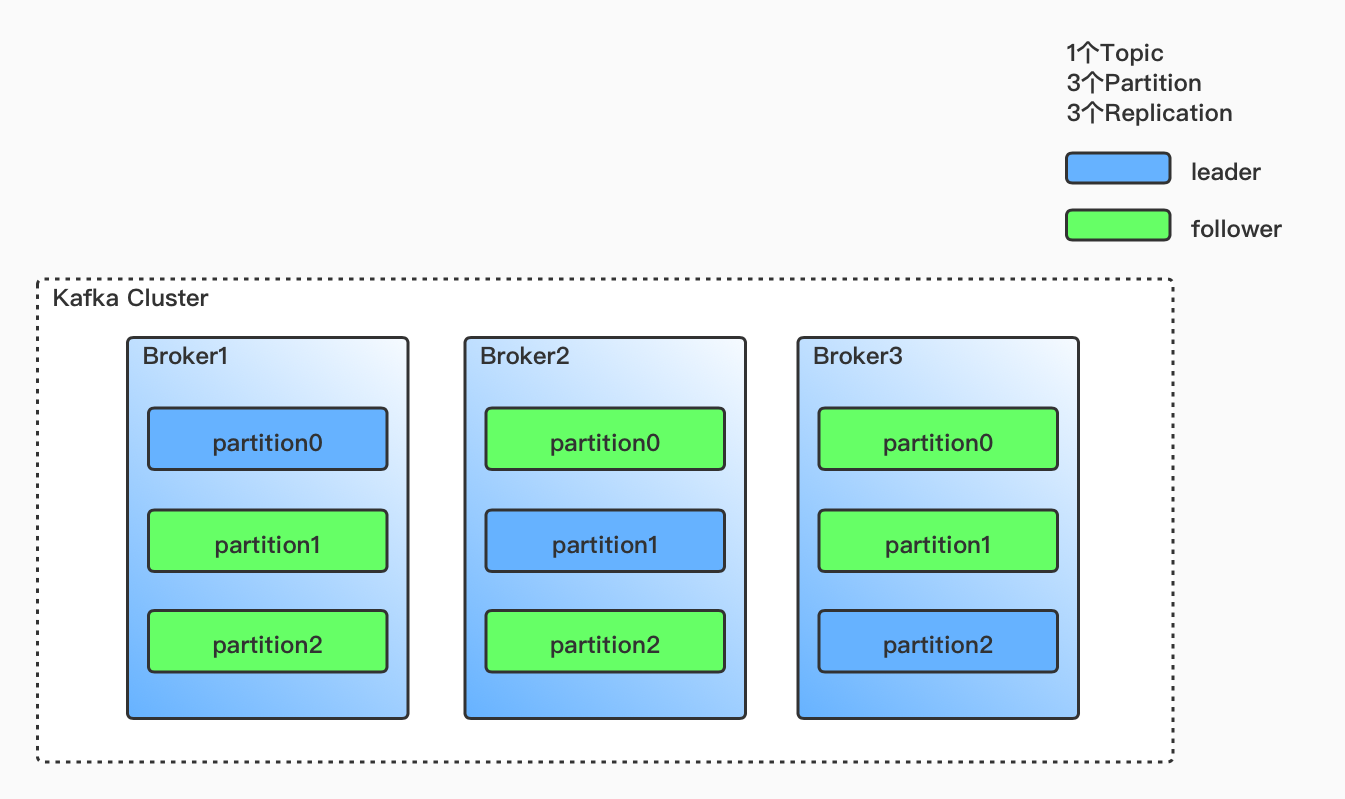
ISR & HW & LEO
AR(Assigned Replicas): 分区中的所有副本
ISR(In-Sync Replicas): 所有与leader副本保持一定程度同步的副本
OSR(Out-of-Sync Replicas): 与leader副本同步滞后过多的副本
由此可见,AR = ISR + OSR
leader副本负责维护和跟踪 ISR 集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从 ISR 集合中剔除。如果 OSR 集合中有follower副本追上了leader副本,那么leader副本会把它从 OSR 集合转移至 ISR 集合。默认情况下,当leader副本发生故障时,只有 ISR 集合里的副本才有资格选举为新的leader
HW(High Watermark): 高水位,它标识了一个特定的消息偏移量offset,消费者只能拉取到这个offset之前的消息
LEO(Log End Offset): 它标识当前日志文件中下一条待写入消息的offset
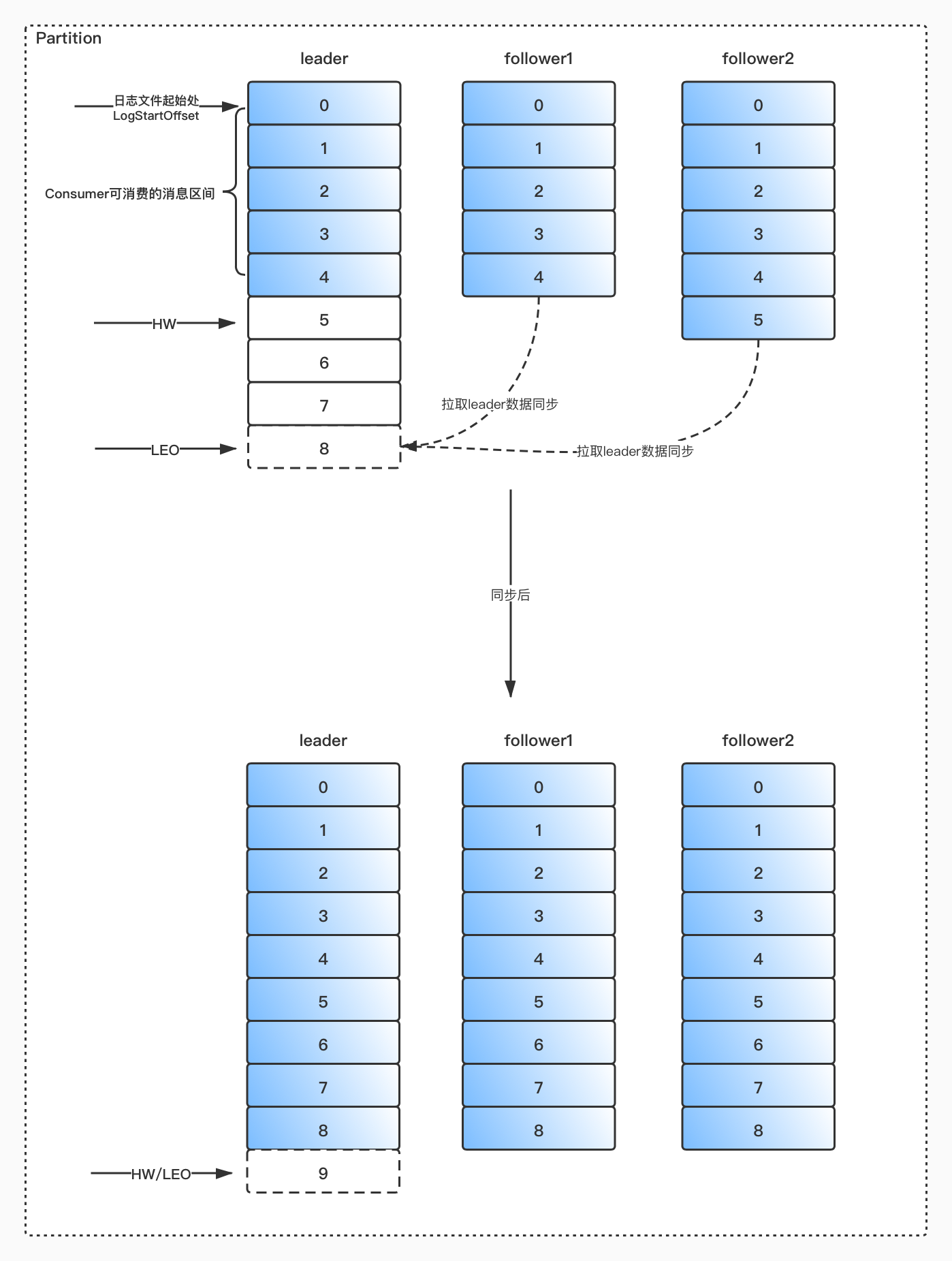
由此可见,
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的
follower副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大的影响了性能。而异步复制的方式下,follower副本异步的从leader副本中复制数据,数据只要被leader副本写入就被认为已经提交成功。在这种情况下,如果follower副本都落后leader副本,突然leader副本宕机,则会造成数据丢失。
Kafka使用的这种ISR的方式则有效的权衡了数据可靠性和性能之间的关系。
Producer
主要工作是向Topic发送消息。但由于副本机制,生产者发送消息怎么样算发送成功呢?在一般的分布式系统中一般采用过半提交的方式确保,既一半以上的副本确认成功才算消息提交成功,但Kafka中并未提供这种机制。Kafka可以通过以下参数配置保障:
-
Producer提供配置acks参数acks=0生产者只要将消息发送出去,无需等待任何副本的确认,即算发送成功。此方式吞吐量最大、性能最好,但kafka服务抖动时容易丢消息acks=1默认。生产者将消息发送出去,只需副本中的leader确认,即算发送成功。此方式吞吐量和性能优秀,但当leader挂时会造成小部分消息丢失acks=all生产者将消息发送出去,需要ISR中的副本全部确认,即算发送成功。此方式吞吐量和性能差,但稳定性最高,消息不容易丢失
-
Broker提供配置replica.lag.time.max.ms参数如果一个
follower没有发送任何fetch请求,或者至少在这段时间内没有消耗到leaders日志结束偏移量,那么leader将从ISR中删除follower
Consumer
在Kafka中,1个Partition只能被1个消费线程消费。消费线程主动pull数据,而非Kafka Server主动push数据,这样消费者可以根据自己的消费能力消费数据。如果有消息堆积,也方便开发人员对消费者及时管理。
如果消费线程大于分区数,则多余的消费线程将空闲;如果消费线程小于分区数,则有部分消费线程将消费多个分区的数据;如果消费线程等于分区数,则刚刚好一个消费线程对应一个分区,这也是最理想的情况。
这样做的好处是offset偏移量方便管理且简单,消费数据的分配及提交offset无需事务保障,也提高了效率。
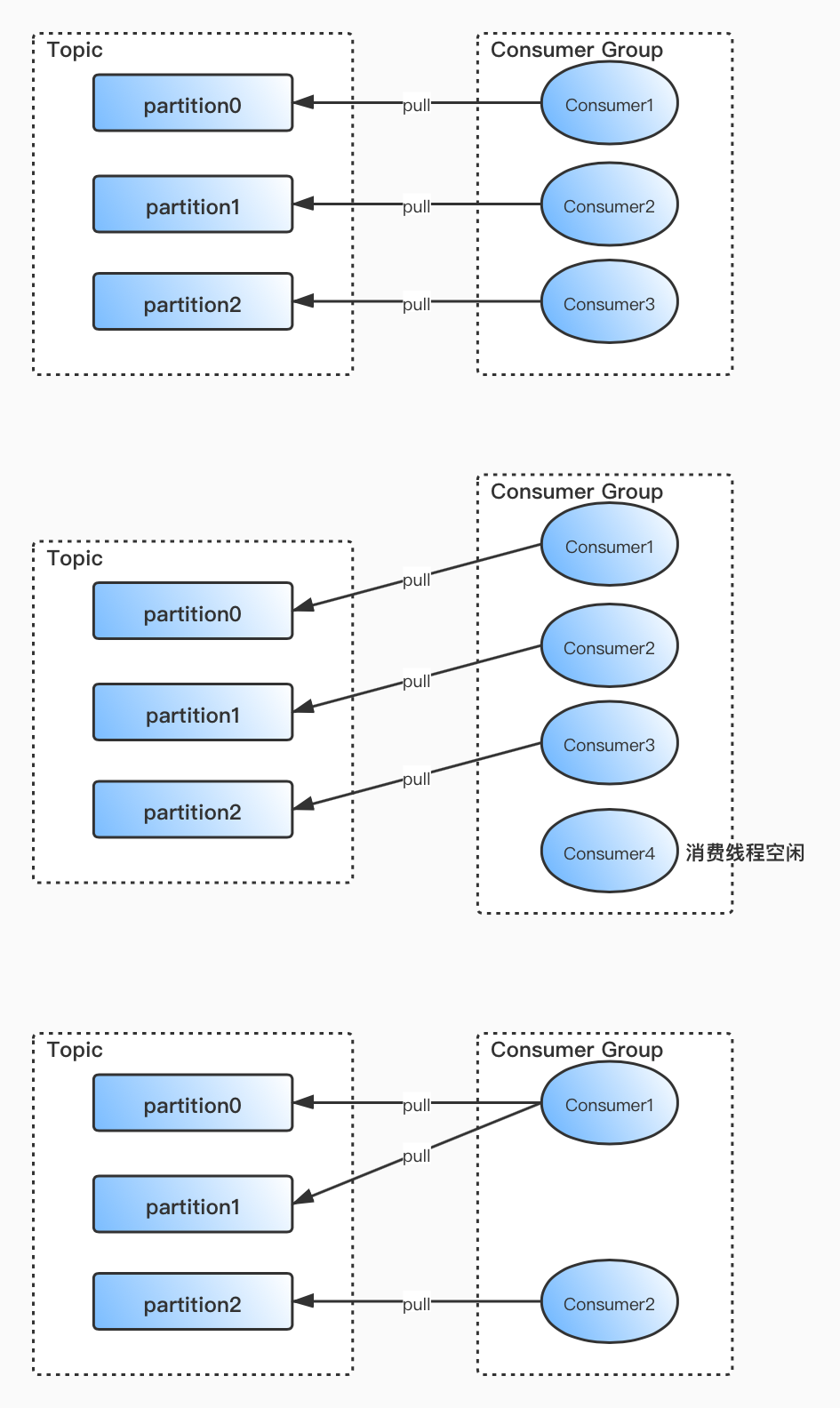
提交offset
由于消费者是主动pull数据,因此每个分区的offset由对应的消费者线程维护,每个消费线程需要记录消费到当前分区的偏移量offset。
在早起Kafka的版本中,每个分区的offset由对应的消费线程维护在zk上。但由于zookeeper的单节点写的特性(只有leader才能处理写请求),所以zookeeper不适合大量数据的频繁写。
之后在Kafka的版本中,每个分区的offset由对应的消费线程维护在__consumer_offset主题中。
结语
以上就是Kafka在整个架构之美的其中一部分,设计还是相当巧妙的。当然涉及到Kafka的东西还有很多。
比如,Kafka在之后版本中逐步在降低对zookeeper的依赖。例如分区副本的选举,在之前的版本中,都是依赖zookeeper操作的。但如果Broker上的Topic过多,一旦Broker宕机将会触发大量Watcher事件,从而引起惊群效应,会导致巨大的服务器性能消耗和网络冲击。因为zookeeper的特性,Kafka选择将各种选举机制都依靠自己解决。
Kafka值得考究、学习和思考的地方还有很多,之后会一一整理分享出来。